






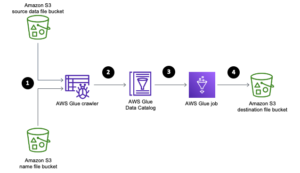
 What is an S3 Bucket?
What is an S3 Bucket?
Amazon Simple Storage Service (S3) is a Container that can be maintained and accessed over the Internet. Amazon S3 provides a web service that can be used to store the data. S3 in Amazon has two entities called buckets and objects. Objects are stored inside buckets.
Steps to Create AWS S3 Bucket and Upload CSV File
Step 1: Sign in to the AWS Management Console
Step 2: Select S3 to open the Amazon S3 console, and choose Create Bucket.
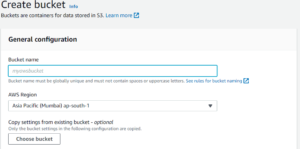
Step 3: Type a bucket name in Bucket Name (name must be unique) and choose the desired Region. Scroll down and click on Create Bucket.
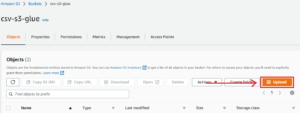
Step 4: Now that the bucket has been created, go inside your bucket and click on Upload to upload your CSV file.
Here is the CSV file in the S3 bucket as illustrated below.
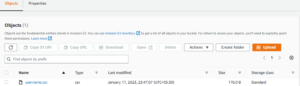
What is AWS Glue Crawler?
A crawler is used to extract data from a source, analyze that data, and then ensure that the data fits a particular schema or structure that defines the data type for each variable in the table.
- Set Up Crawler in AWS Glue
- Go to AWS Glue Console and Click on Create crawler.
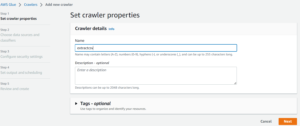
- Now Set crawler properties of Crawler details, Give the Name in the field, then click Next.
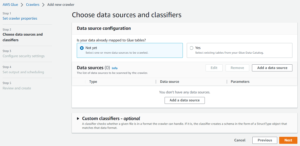
- Now Choose data sources and classifiers Add a data source then a new modal opens like below attached image.
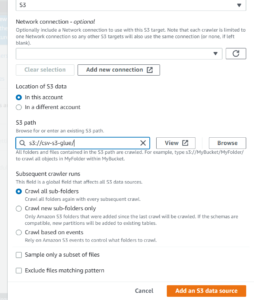
- Then simply add your S3 data source. and it looks like this, then click again Next.
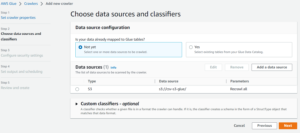
- In Configure security settings you have to choose the IAM role and click again Next.
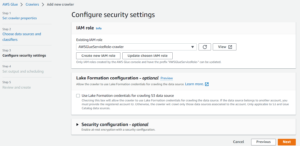
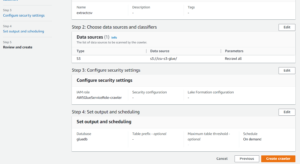
- Now Set output and scheduling and Select your Target Database.
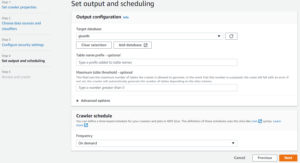
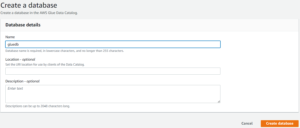
- If you don’t have a database then you can create a database by clicking on Add database tab after Give a Name of your database and just click Create database.
- And Now Review your Crawler and simply click Create crawler.
- Now your Crawler successfully created then click Run Crawler.
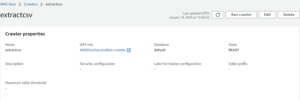
Once the crawler starts running , it takes a few minutes to create a table within the database.
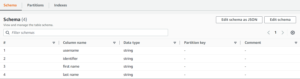
- Now go to the Glue Data Catalog > Databases > Tables
After the Successfully Crawler run, you will see your new table created that is mapped to the database you specified. Here, the schema is being detected automatically.
What is Athena?
Amazon Athena is a server less and data analysis tool used to process complex queries in a relatively short amount of time. Hence, there is no hassle to set up, and no infrastructure management is required. It is not a database service. Therefore, you pay for the queries you run. You just point your data into S3, define the necessary schema, and you are good to go with a standard SQL.
- Now, we have to go AWS Athena
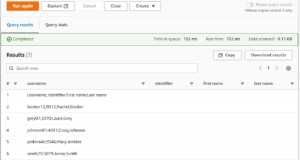
- Go to Athena editor and choose Data source and database, then it simply shows a table on table and views tab.
- After that we have to write the query and run.
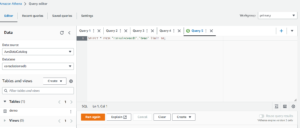
- Here is the visual: by running the query it gets all the data from S3 bucket through AWS Glue Catalog.
What is AWS Glue Ray?
AWS Glue Ray is a new engine on AWS Glue. We can use AWS Glue for Ray to process large datasets with Python and other Python libraries. AWS Glue is a serverless, scalable data integration service which is used to discover, prepare, and integrate data from multiple sources. AWS Glue for Ray combines that serverless option for data integration with Ray, which is a popular open-source compute framework that helps you scale Python workloads.
Now we have to create a job in Aws Glue, just follow the below steps.
Step 1
- Go to your AWS console and search AWS Glue,then open AWS Glue Console
- After that you have to change your region to N. Virginia(us-east-1)
- Go Data Integration and ETL => Jobs
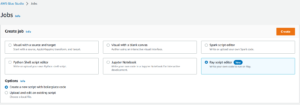
Step 2
- On Create job Select Ray script editor and within Options Choose Create a new script with boilerplate code(you can also upload your existing code file using upload and edit an existing script).
- Then click the Create Button Above.
- Now your screen looks like this.
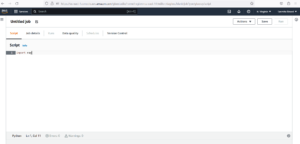
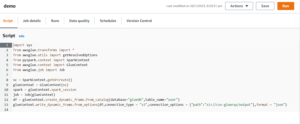
In the script section write your code what you want to do.But In this Blog we have to get the record from Glue Crawler and Write that data in s3 Bucket in json format(If we talk about format it can be any format like CSV,Json).
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
df = glueContext.create_dynamic_frame.from_catalog(
database="database_name", table_name="table_name"
)
glueContext.write_dynamic_frame.from_options(
df,
connection_type="s3",
connection_options={"path": "s3://prefix/output"},
format="json",
)
Add the given code under the Script section.
Now we have to move the Job Details tab. Give the Name of Job,Choose the given Role which can give the permissions to Glue Ray. after that no need to change. Now save your Job.
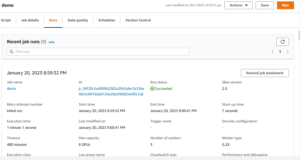
Once the Job Create then check , it looks like this.

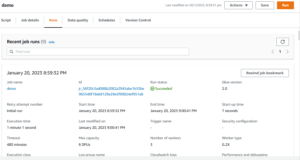
Then click Run your job start Running and When it’s complete in the Run Tab you can check there your Run status.
Now check Run status is Succeeded.
Now go to S3 Bucket and check and the file is now uploaded successfully.
Conclusion:
In this example, you have seen:
- How to crawl data in an S3 bucket with Glue and run SQL queries using Athena.